There was lots of interest in a blog post earlier this year about
preserving Google Docs.
Often the issues we grapple with in the field of digital preservation are not what you'd call 'solved problems' and that is what makes them so interesting. I always like to hear how others are approaching these same challenges so it is great to see so many comments on the blog itself and via Twitter.
This time I'm turning my focus to the related issue of
Google Sheets. This is the native spreadsheet application for Google Drive.
Why?
Again, this is an application that is widely used at the University of York in a variety of different contexts, including for academic research data. We need to think about how we might preserve data created in Google Sheets for the longer term.
How hard can it be?
Quite hard actually - see
my earlier post!
Exporting from Google Drive
For Google Sheets I followed a similar methodology to Google Docs. Taking a couple of sample spreadsheets and downloading them in the formats that Google provides, then examining these exported versions to assess how well specific features of the spreadsheet were retained.
 |
| I used the File...Download as... menu in Google Sheets to test out the available export formats |
The two spreadsheets I worked with were as follows:
- A simple spreadsheet which staff had used to select their menu choices for a celebration event. This consisted of just one sheet of data and no particularly advanced features. The sheet did include use of the Google Drive comments facility
- My flexitime sheet which is provided by my department and used to record the hours I work over the course of the year. It seems to be about as complex as it gets and includes a whole range of features: multiple sheets (that reference each other), controlled data entry through drop down lists, calculations of hours using formula, conditional formatting (ie: specific cells turning red if you have left work too early or taken an inadequate lunch break), code that jumps straight to today's date when you first open it up.
Here is a summary of my findings:
Microsoft Excel - xlsx
I had high hopes for the xlsx export option - however, on opening the exported xlsx version of my flexisheet I was immediately faced with an error message telling me that the file contained unreadable content and asking whether I wanted to recover the contents.
 |
| This doesn't look encouraging... |
Clicking 'Yes' on this dialogue box then allows the sheet to open and another message appears telling you what has been repaired. In this case it tells me that a formula has been removed.
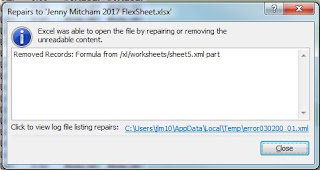 |
| Excel can open the file if it removes the formula |
This is not ideal if the formula is considered to be worthy of preservation.
So clearly we already know that this isn't going to be a perfect copy of the Google sheet.
This version of my flexisheet looks pretty messed up. The dates and values look OK, but none of the calculated values are there - they are all replaced with "#VALUE".
The colours on the original flexisheet are important as they flag up problems and issues with the data entered. These however are not fully retained - for example, weekends are largely (but not consistently) marked as red and in the original file they are green (because it is assumed that I am not actually meant to be working weekends).
The XLSX export does however give a better representation of the more simple menu choices Google sheet. The data is accurate, and comments are present in a partial way. Unfortunately though, replies to comments are not displayed and the comments are not associated with a date or time.
Open Document Format - ods
I tried opening the ODS version of the flexisheet in LibreOffice on a Macbook. There were no error messages (which was nice) but the sheet was a bit of a mess. There were similar issues to those that I encountered in the Excel export though it wasn't identical. The colours were certainly applied differently, neither entirely accurate to the original.
If I actually tried to use the sheet to enter more data in, the formula do not work - they do not calculate anything, though it does appear that the formula itself appears to be retained. Any values that are calculated on the original sheet are not present.
Comments are retained (and replies to comments) but no date or time appears to be associated with them (note that the data may be there but just not displaying in LibreOffice).
I also tried opening the ODS file in Microsoft Office. On opening it the same error message was displayed to the one originally encountered in the XLSX version described above and this was followed by notification that “Excel completed file level validation and repair. Some parts of this workbook may have been repaired or discarded.” Unlike the XLSX file there didn't appear to be any additional information available about exactly what had been repaired or discarded - this didn't exactly fill me with confidence!
PDF document - pdf
When downloading a spreadsheet as a PDF you are presented with a few choices - for example:
- Should the export include all sheets, just the current sheet or current selection (note that current sheet is the default response)
- Should the export include the document title?
- Should the export include sheet names?
To make the export as thorough as possible I chose to export all sheets and include document title and sheet names.
As you might expect this was a good representation of the values on the spreadsheet - a digital print if you like - but all functionality and interactivity was lost. In order to re-use the data, it would need to be copied and pasted or re-typed back into a spreadsheet application.
Note that comments within the sheet were not retained and also there was no option to export sheets that were hidden.
Web page - html
This gave an accurate representation of the values on the spreadsheet, but, similar to the PDF version, not in a way that really encourages reuse. Formula were not retained and the resulting copy is just a static snapshot.
Interestingly, the comments in the menu choices example weren't retained. This surprised me because when using the html export option for Google documents one of the noted benefits was that comments were retained. Seems to be a lack of consistency here.
Another thing that surprised me about this version of the flexisheet was that it included hidden sheets (I hadn't until this point realised that there were hidden sheets!). I later discovered that the XLSX and ODS also retained the hidden sheets ...but they were (of course) hidden so I didn't immediately notice them!
Tab delimited and comma separated values - tsv and csv
It is made clear on export that only the current sheet is exported so if using this as an export strategy you would need to ensure you exported each individual sheet one by one.
The tab delimited export of the flexisheet surprised me. In order to look at the data properly I tried importing it into MS Excel. It came up with a circular reference warning which surprised me - were some of the dynamic properties of the sheets being somehow retained (all be it in a way that was broken)?
 |
| A circular reference warning when opening the tab delimited file in Microsoft Excel |
Both of these formats did a reasonable job of capturing the simple menu choices data (though note that the comments were not retained) but neither did an acceptable job of representing the complex data within the flexisheet (given that the more complex elements such as formulas and colours were not retained).
What about the metadata?
I won't go into detail again about the other features of a Google Sheet that won't be saved with these export options - for example information about who created it and when and the complete revision history that is available through Google Drive - this is covered in a
previous post. Given my findings when
I interviewed a researcher here at the University of York about their use of Google Sheets, the inability of the export options to capture the version history will be seen as problematic for some use cases.
What is the best export format for Google Sheets?
The short answer is 'it depends'.
The export options available all have pros and cons and as ever, the most suitable one will very much depend on the nature of the original file and the properties that you consider to be most worthy of preservation.
- If for example the inclusion of comments is an essential requirement, XLSX or ODS will be the only formats that retain them (with varying degrees of success).
- If you just want a static snapshot of the data in its final form, PDF will do a good job (you must specify that all sheets are saved), but note that if you want to include hidden sheets, HTML may be a better option.
- If the data is required in a usable form (including a record of the formula used) you will need to try XLSX or ODS but note that calculated values present in the original sheet may be missing. Similar but not identical results were noted with XLSX and ODS so it would be worth trying them both and seeing if either is suitable for the data in question.
It should be possible to export an acceptable version of the data for a simple Google Sheet but for a complex dataset it will be difficult to find an export option that adequately retains all features.
Exporting Google Sheets seems even more problematic and variable than Google Documents and for a sheet as complex as my flexisheet it appears that there is no suitable option that retains the functionality of the sheet as well as the content.
So, here's hoping that native Google Drive files appear on the list of World's Endangered Digital Species...due to be released on International Digital Preservation Day! We will have to wait until tomorrow to find out...
A disclaimer: I carried out the best part of this work about 6 months ago but have only just got around to publishing it. Since I originally carried out the exports and noted my findings, things may have changed!
Jenny Mitcham, Digital Archivist



